2.3.1. Streaming data, edge computing and online learning¶
Streaming data—generated continuously from sensors, IoT devices, and real-time transactions—requires low-latency processing due to its high velocity and unbounded nature. Edge computing addresses these demands by decentralizing computation to devices near data sources, enabling faster response times, reduced cloud dependency, and bandwidth optimization.
2.3.1.1. Edge computing on data stream¶
As a decentralized counterpart to centralized cloud computing, edge computing enhances data privacy and security by processing information locally (Figure 2.18). This approach significantly reduces network transmissions, minimizes attack surfaces, and strengthens defenses against cyber threats. However, despite these advantages, edge computing’s application in streaming data processing remains constrained by three key factors: limited data throughput, heterogeneous computational capabilities, and diverse hardware architectures across edge devices. Addressing these limitations would enable direct, real-time manipulation of device-generated data streams, thereby unlocking the full potential of localized artificial intelligence (AI) for instant decision-making.
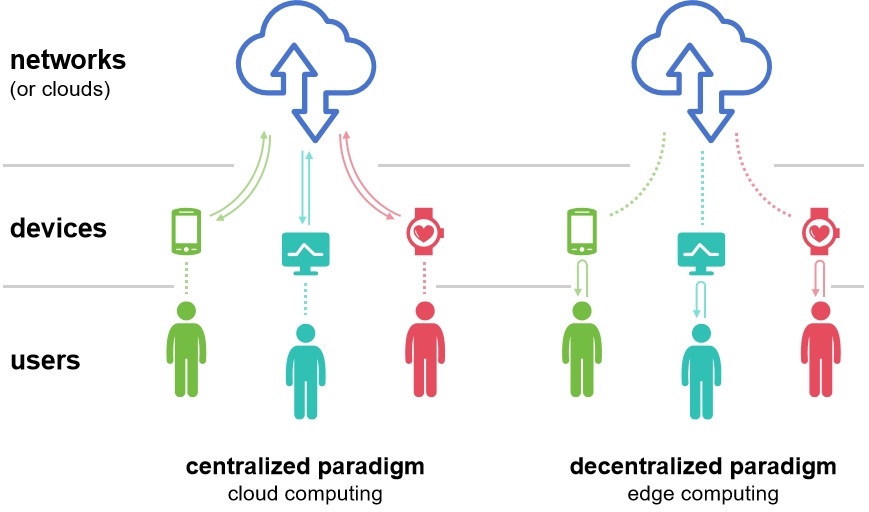
Figure 2.18 cloud and edge computing paradigm¶
2.3.1.2. Incremental online learning and edge AI¶
Incremental online learning (IOL) and edge artificial intelligence (Edge AI) represent a transformative paradigm for deploying adaptive machine learning models in resource-constrained, latency-sensitive environments. Unlike traditional cloud-centric approaches reliant on batch training with static datasets, IOL enables models to update dynamically using streaming data, while edge AI embeds lightweight inference and training capabilities directly on edge devices. This synergy addresses critical challenges in real-time data processing, such as latency reduction, bandwidth optimization, and privacy preservation.
The interplay among streaming data, edge computing, and online learning is schematically depicted in Figure 2.19. This framework highlights how edge-deployed AI models aim to balance two critical objectives: (1) efficient utilization of constrained computational resources (e.g., limited memory, energy budgets), and (2) real-time responsiveness with self-adaptation to concept drift (e.g., evolving sensor patterns or environmental dynamics).

Figure 2.19 streaming data, edge computing and AI¶
2.3.1.3. Edge intelligence implementation strategies¶
Real-world edge intelligence systems rarely rely on a single technique—they weave together streaming data, adaptive learning, and hardware-aware optimizations to address domain-specific constraints. We now dissect three canonical strategies that epitomize how these components interact, balancing latency, resource efficiency, and privacy.
2.3.1.3.1. Real-time priority system¶
Latency-sensitive edge systems require:
hard deadlines: predictable execution windows (20ms-1s)
guaranteed throughput: processing rate ≥ peak data ingestion rate
decoupled architecture: isolation between data ingestion/compute stages
The template in Code 2.24 enforces these requirements through thread-safe queues and modular processing:
from queue import Queue
consumer, processing, model = Queue(), ..., ...
...
while True:
while not consumer.empty():
_tmp = processing(consumer.get())
model.train_or_predict(_tmp)
This pattern’s value lies in its field-agnostic structure. The same queue-driven pipeline can power endoscopic video
analysis in surgical robots, defect detection on manufacturing lines, or obstacle avoidance in autonomous
vehicles—simply by substituting domain-specific processing logic and model implementations while
retaining the core deadline control mechanism.
2.3.1.3.2. Resource-aware hybrid pipelines¶
Balancing immediate inference needs with periodic model refinement requires hybrid architectures that dynamically allocate resources based on operational context (e.g., power availability, CPU load). These pipelines prioritize critical tasks while opportunistically utilizing idle resources for model improvement. Its technical mechanisms are generally featured as:
queue prioritization: split data streams into urgent/non-urgent queues
dynamic batching: aggregate training data during low-activity periods
power-sensitive scheduling: trigger model updates only when external power is available
The template in Code 2.25 enforces these requirements through thread-safe queues and modular processing:
from queue import Queue
urgent, delay, device, model = Queue(maxsize=100), Queue(maxsize=1000), ..., ...
...
while True:
while not urgent.empty():
_tmp = model.predict(urgent.get())
...
if device.power_source == 'external' and device.is_in_idle():
while not delay.empty():
_tmp = dynamic_batch(delay)
model.train(_tmp)
This pattern’s modular design allows seamless adaptation across domains. For instance, surgical robots may prioritize
real-time tissue segmentation (urgent queue) while deferring post-operative model updates to charging intervals
(delay queue). Similarly, smart home gateways could process security alerts immediately but delay learning
user behavior patterns until nighttime.
By retaining the core mechanisms—priority queues, dynamic batching, and power-aware triggers—developers need only redefine domain-specific handlers for urgent tasks, delayed operations, and hardware interfaces, ensuring adaptability without compromising deterministic execution guarantees.
2.3.1.3.3. Federated edge adaptation¶
Decentralized edge intelligence systems require:
data isolation: no raw data leaves source devices
concept drift resilience: local adaptation to device-specific data shifts
secure knowledge fusion: cryptographic aggregation of localized updates
The template in Code 2.26 implements these requirements through encrypted parameter exchange and localized learning:
class FederatedCoordinator:
def __init__(self):
self.nodes, self.global_state = [EdgeNode(), ...], None
def aggregate(self):
encrypted_updates = [n.get_encrypted() for n in self.nodes]
self.global_state = secure_aggregate(encrypted_updates)
def distribute(self):
for n in self.nodes:
n.receive(encrypt(self.global_state))
class EdgeNode:
def __init__(self):
self.local_model, self.stream_queue, self.cache = ..., ..., ...
def get_encrypted(self):
update = self._compute_update()
return encrypt(update)
def receive(self, encrypted_state):
global_update = decrypt(encrypted_state)
self.local_model.merge(global_update)
def _compute_update(self):
while not self.stream_queue.empty():
data = self.stream_queue.get()
if self._detect_drift(data):
self._adapt_model()
self.cache.store(self.local_model.learn(data))
return self.cache.export()
def _adapt_model(self):
self.local_model = adjust_structure(
self.local_model,
context=self.stream_queue.stats()
)
Federated edge adaptation establishes a privacy-preserving framework for decentralized intelligence systems, where edge devices collaboratively evolve models without exposing raw data. By enforcing data isolation through encrypted parameter exchange, enabling concept drift resilience via localized model adjustments, and ensuring secure knowledge fusion via cryptographic aggregation, this architecture bridges the gap between distributed autonomy and collective intelligence. The provided template supports diverse learning paradigms—from Bayesian updates to online rule refinement—by decoupling domain-specific implementations (e.g., medical image analysis, industrial IoT monitoring) from core mechanisms like drift detection and secure synchronization. This balance of adaptability and security positions federated edge adaptation as a foundational pillar for next-generation applications demanding both privacy and real-time responsiveness.
- Authors:
Chen Zhang
- Version:
0.0.6
- Created on:
Apr 26, 2025